

String Searching Algorithm
매칭 솔루션은 사용내역과 권리음악정보의 곡명에 단어를 비교 분석하여 매칭 Rate를 구하고
곡명이 100% 일치하는 정보를 후보군으로 만들어 가수명, 앨범명 순으로 비교 분석하여 Rate를 구하는 알고리즘을 적용하였다.
단어 사이에 있는 괄호(대, 중, 소), / , 쉼표(,) 등은 삭제하고 비교 분석한다.
이 과정을 거치면 곡명, 가수명, 앨범명에 대한 매칭율 값을 얻을 수 있고 곡명이 100%일치하는 정보 중 가수명 매칭율과 앨범명 매칭율을 비교하여 매칭 결과를 결정한다.
또한 1 Byte문자와 2Byte문자를 처리 할 수 있도록 설계되어 한글, 영문, 다국어를 처리 할 수 있다.
알고리즘은 매칭된 정보를 특정한 코드로 관리하기 때문에 추적이 가능하며 같은 사용내역 정보가 입력되었을 때 매칭 성능을 최적화 할 수 있다.
| 곡명 | 가수명 | 앨범명 | 처리 |
|---|---|---|---|
| 100% 일치 | 100% 일치 | 100% 일치 | |
| 100% 일치 | 100% 일치 | 60% 이상 일치 | 편집앨범 |
| 100% 일치 | 100% 일치 | 40~50% 일치 | 앨범명 검증 |
| 100% 일치 | 80% 이상 일치 | 100% 일치 | 가수명 검증 |
| 100% 일치 | 60% 이상 일치 | 100% 일치 | 가수명 검증 |
| 100% 일치 | 80% 이상 일치 | 80% 이상 일치 | 가수명, 앨범명 검증 |
| 100% 일치 | 60% 이상 일치 | 60% 이상 일치 | 가수명 앨범명 검증 |
위의 표와 같이 곡명, 가수명, 앨범명의 매칭율의 상관관계를 분석하여 검증하고 학습시킨 결과 매칭율과 정확도가 향상되었다.
하지만 알고리즘으로는 처리 할 수 없는 영역도 존재하여 이를 보완하려면 매칭된 결과 데이터를 학습데이터로 설정하여 AI 학습모델을 구현하고 이를 해결 할 수 있는 솔루션이 필요하다.
개발사는 학습모델을 최적화하여 매칭율의 정확도 향상 시킬 계획이며, 정보의 의미성 분석, 오타 및 특수문자 처리, 권리음악 정보의 정제, 가수명 정보의 인덱싱를 통하여 좀더 정확한 매칭 성능을 구현할 수 있었다.
사용내역 정보와 권리음악 정보의 매칭 프로세스
매칭 프로세스는 곡명이 100% 일치한 정보를 기준으로 진행되며 아래의 프로세스를 통하여 매칭 결과 값을 구하고 매칭을 적용한다
- 가. 사용내역과 권리음악정보의 곡명을 비교하여 매칭율 계상
- 나. 곡명 100% 매칭율 정보 중 가수명 매칭율이 가장 높은 정보 우선
- 다. 곡명, 가수명 매칭율이 같을 경우 앨범명 매칭율이 가장 높은 정보 우선
- 라. 곡명이 100% 일치하고 앨범명 매칭율이 60% 이상일 경우 가수명 검증
- 마. 곡명이 100% 일치하고 가수명, 앨범명 매칭율이 60% 이하일 경우 검증
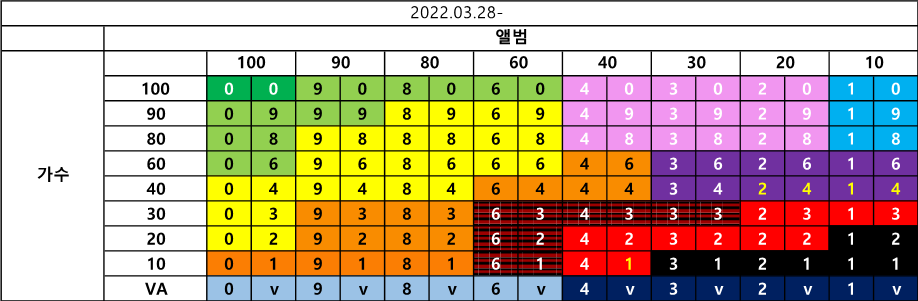
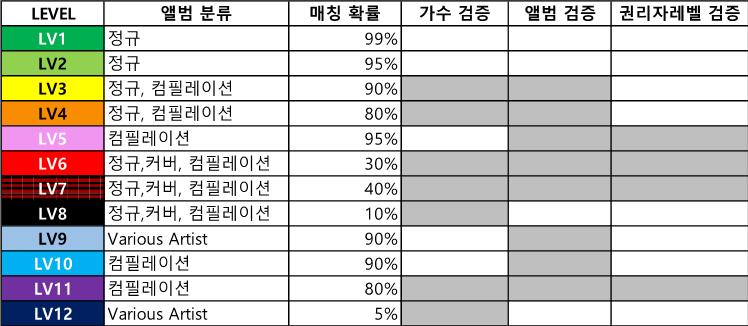
컬러레벨별 매칭 Rate 설정
곡명이 100% 일치하는 것을 전제로 앨범과 가수의 매칭율을 산정하고 정확도를 분석하여 아래와 같은 레벨을 설정하고 이를 컬러로 지정하였다. 또한 수치로 레벨을 정하여 12단계로 설정하였다.
학습모델 도입
String 매칭 알고리즘이 처리 할 수 없는 영역은 AI 학습모델을 도입하여 처리하여야 한다.
아래와 같은 경우는 AI 학습모델을 도입하여 처리할 수 영역으로 구분한다.
- 가. 곡명이 100% 일치하나 가수명, 앨범명이 60% 이하로 매칭 된 경우
- 나. 가수명이 Various Artist, Unknown, Null 값으로 매칭이 불가 할 경우
- 다. 사용내역과 권리음악정보에 오타가 발생한 경우
- 라. 사용내역이 곡명만 입력된 경우
- 마. 사용내역의 입력된 단어의 의미론적 형태소 분석이 필요한 경우
가수명 정보의 Artist String과 Stopword의 추출
가수명의 매칭율은 매칭의 True와 False 값을 판단하는 중요한 Factor이다.
가수명 매칭율의 정확도(Precision)를 높이기 위하여 매칭 확정된 가수명 정보를 분석하여 실제로 매칭에 영향을 미치는 Artist String과 매칭율의 정확도를 떨어뜨리는 Stopword를 추출하여 매칭율을 계상하여야 한다.
또한 가수명 정보를 분석하여 가수명의 동일표현 정보를 구축하면 표기법에 의한 가수명의 매칭율이 현저히 낮은 매칭 정보를 정확히 매칭 할 수 있다.
| 사용로그 | 권리음악정보 | Artist String |
|---|---|---|
| 이치현과 벗님들 | 이치현 | A. 이치현 |
| 이치현과 벗님들 | 벗님들 | B. 벗님들 |
| New York Philharmonic Orchestra | London Philharmonic Orchestra | C. Philharmonic Orchestra |
| 소녀시대 | Girls Generation | D. 소녀시대, Girls Generation |
| 지 드래곤(G DRAGON) | 권지용 | E. 지 드래곤, G DRAGON, 권지용 |
- A의 이치현은 Artist String으로 등록할 수 있다.
- B의 경우에도 벗님들은 Artist String으로 등록할 수 있다.
- C의 경우 Philharmonic Orchestra은 매칭율을 떨어뜨리는 문자열이므로 Stopword로 등록하여야 한다.
- 이러한 사례대로 매칭 확정된 가수명을 분석하여 별도의 Artist String과 Stopword 구축하여 이를 검증하여야 한다.
- D, E의 경우는 동일한 표현의 가수명 표기법이지만 가수명 매칭율이 0%인 경우이다.
- 개발사는 현재 아래와 같이 동일 표현 가수명 정보, 가수명 Artist String, Stopword 구축하고 있다.
- 향후 정보들을 검증하여 가수명 매칭 정확율(Precision)을 높일 수 있도록 가수명 매칭 프로세스를 고도화한다면 저작권을 위한 정보 AI 매칭분야 및 음악산업에서 활용할 수 있는 좋은 사례가 될 것이다.