데이터의 분석 및 레이블링
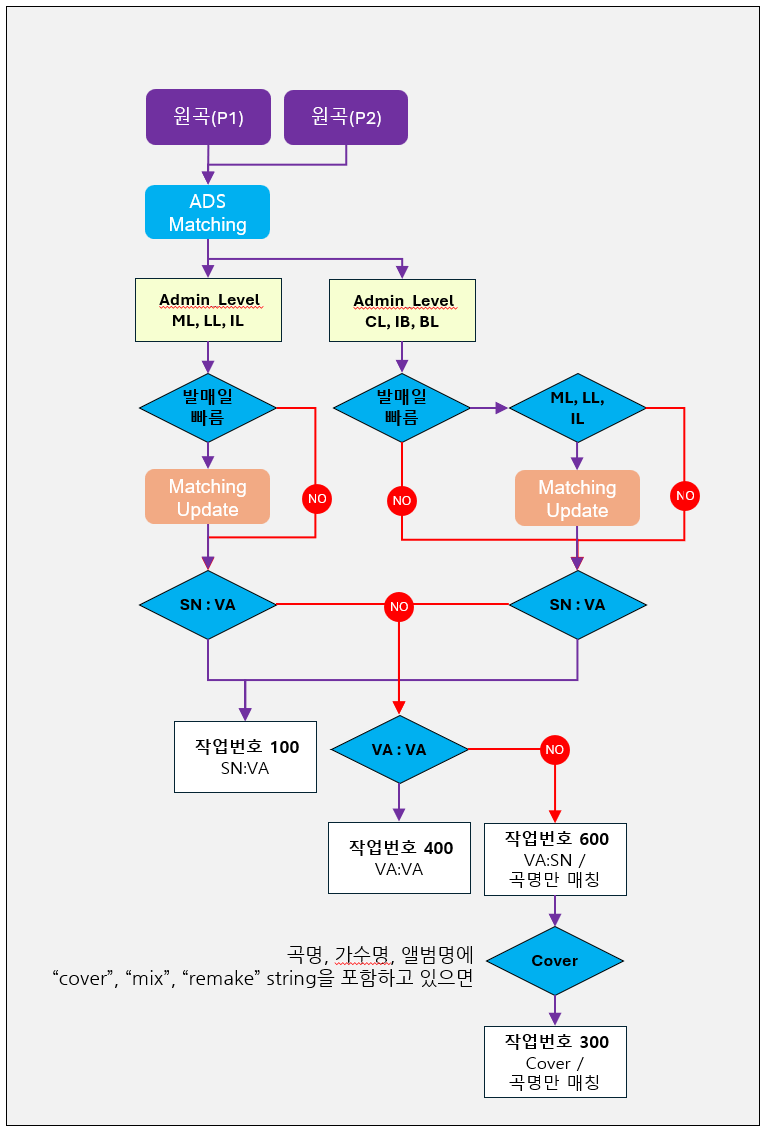
미 매칭 총 곡을 대상으로 String Searching Algorithm으로 곡, 가수, 앨범명의 매칭율을 구한다.
매칭의 전제조건은 곡명의 매칭율을 모두 100%가 되어야 한다.
검증의 정확율을 위하여 학습데이터를 Labeling하여 각 컬러레벨(매칭율)의 매칭 정확도를 측정하고 Entropy 값을 설정한다.
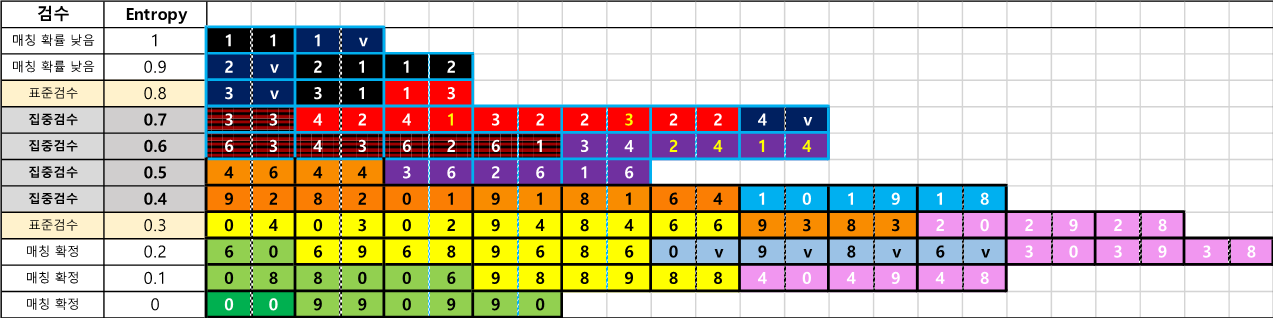
- 가. Entropy란 정보의 불확실성 정도를 나타내는 용어로서 1에 가까울수록 불확실성이 높아지고 0에 가까울수록 불확실성이 낮아진다.
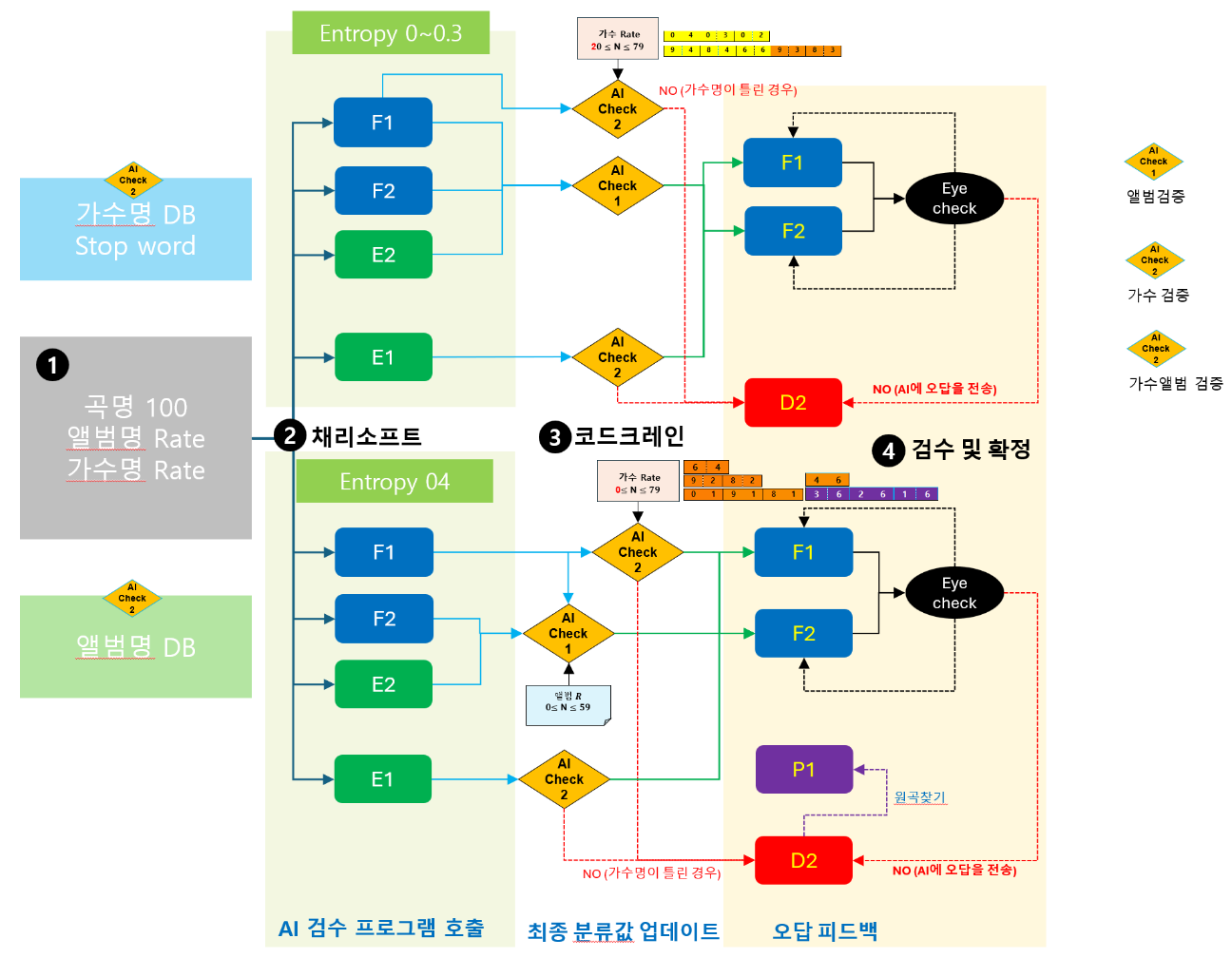
- 나. 0.3과 0.8 : 표준 검수 프로세스로 검수의 강도가 낮으며 AI검수를 진행하여 결과 값을 확정한다.
- 다. 0.4~0.7 : 집중 검수 프로세스로 AI검수와 알고리즘 검수를 순환구조(Back Propagation)로 만들어 검수의 정확도를 높인다.
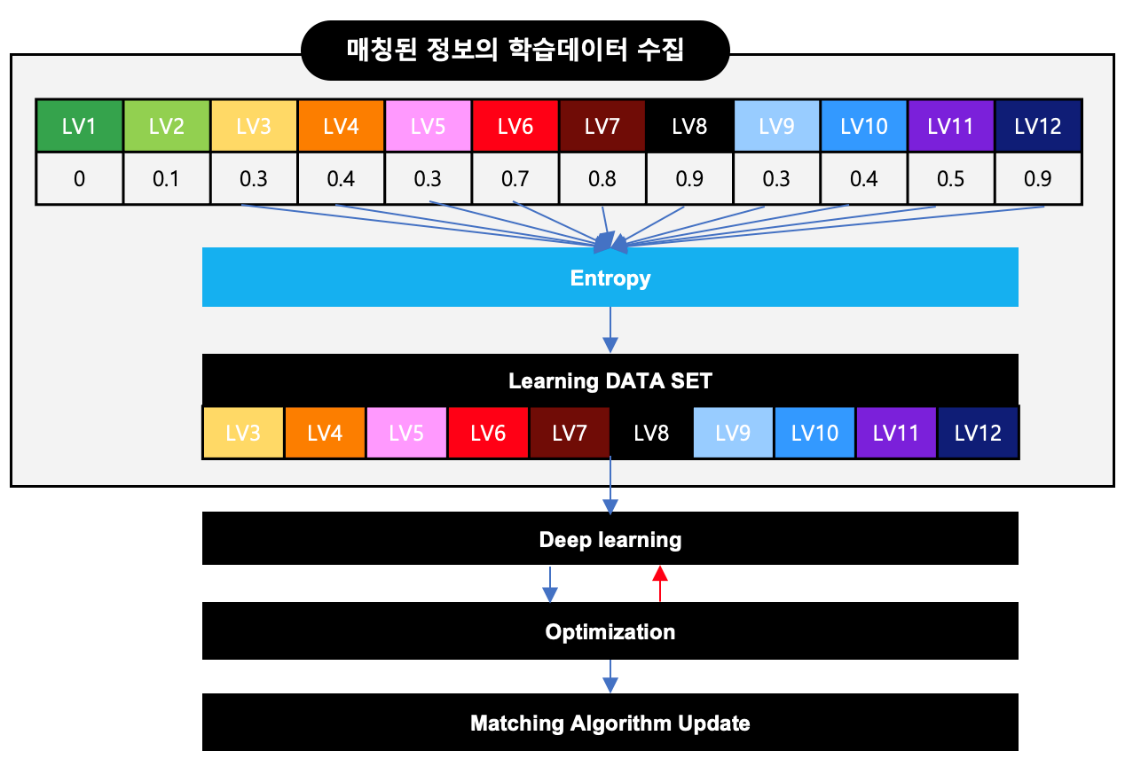
- 라. 곡, 가수, 앨범명의 매칭율과 Entropy 값을 계상하여 분류가 가능한 학습데이터를 수집하고 레이블링하여 딥러닝 Data Set을 구성하였고 Classify 모델을 수립하였다.
Classify 모델을 거쳐 앨범의 유형별로 분류 모델을 만들고 AI 검증 모델을 수립하였다
* 학습데이터의 설정 및 흐름도
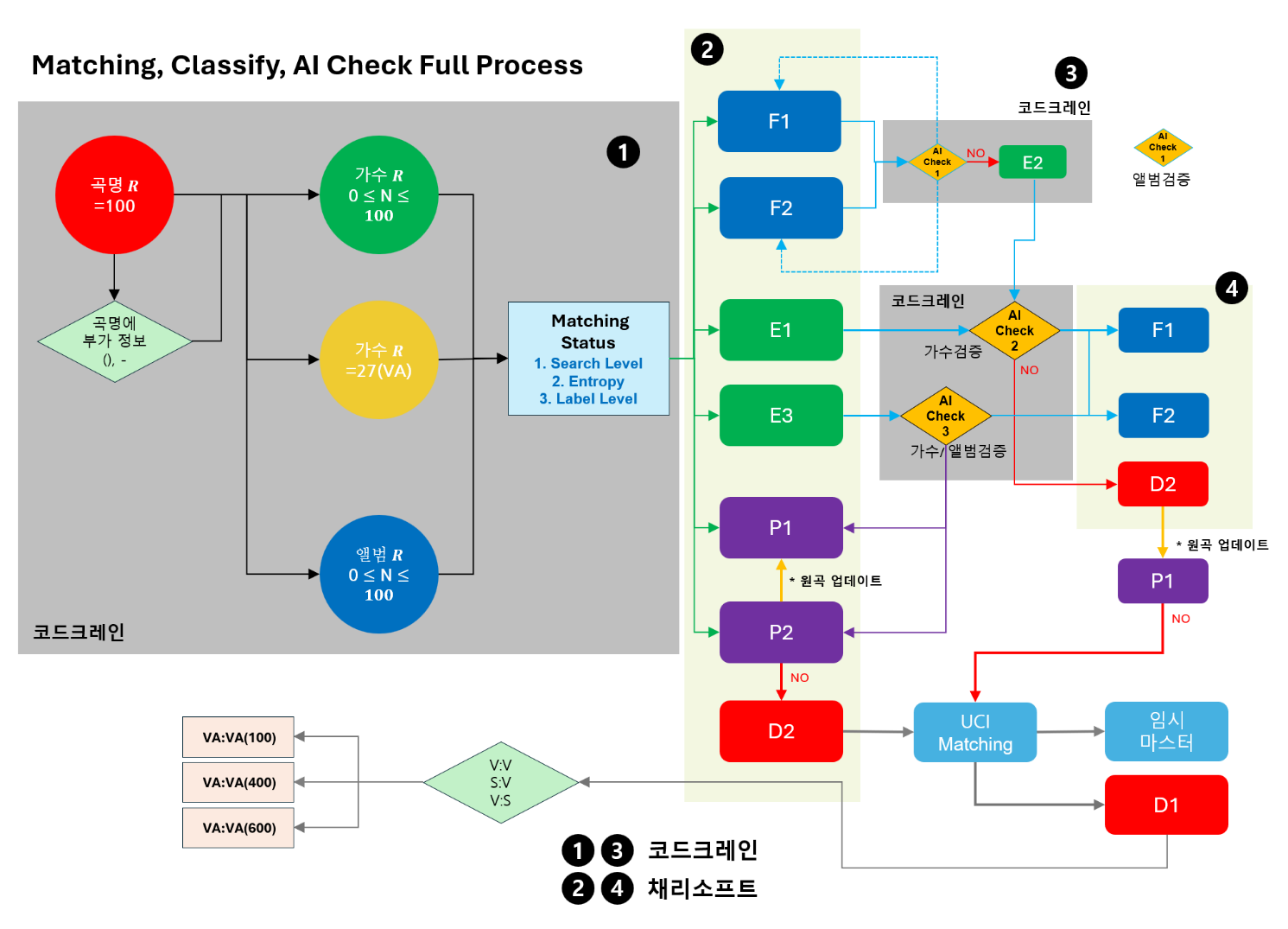
매칭 정보의 Classify(분류)
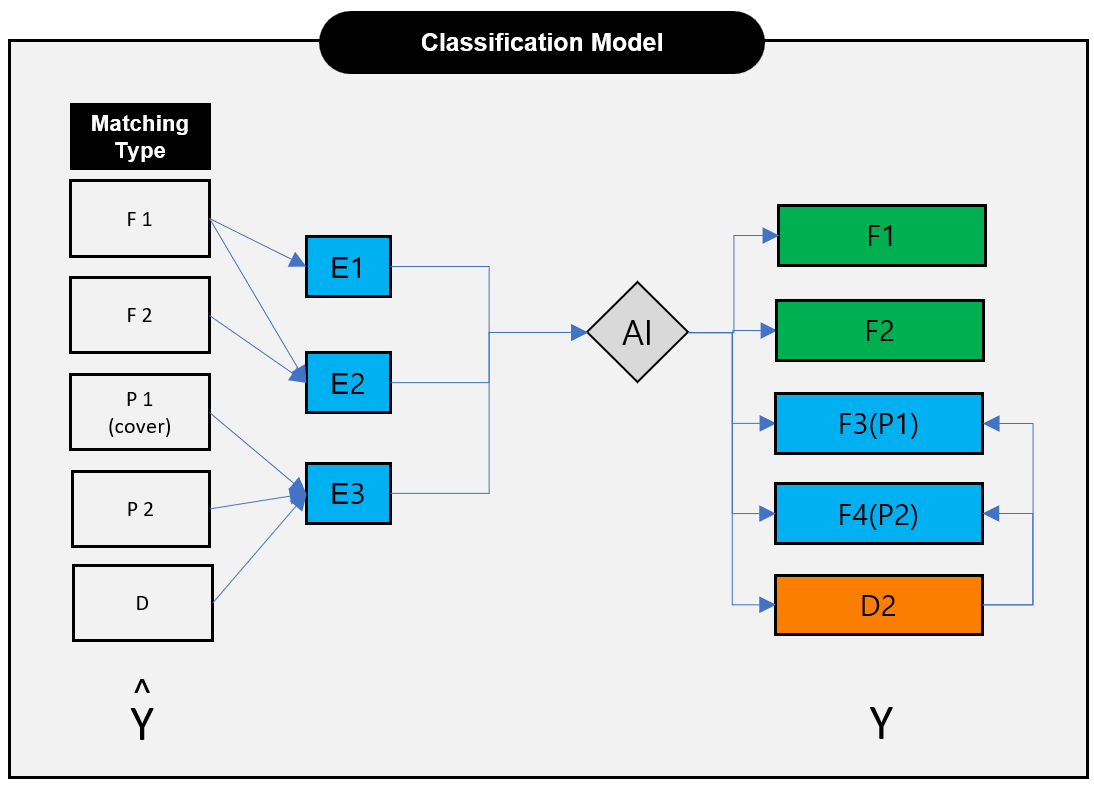
매칭된 정보는 AI Classify로 분류 작업을 거쳐 AI 검증 프로세스를 적용할 수 있는 대상 정보로 분류하였다.
이 프로세스는 앨범의 유형을 분류하는 과정이며 집중적으로 매칭의 True와 False 값을 확정 할 수 있도록 하는 AI 검증 프로세스의 사전 데이터 분류 프로세스라 할 수 있다.
- E1, E2, E3는 AI 집중 검증 학습모델에 적용 할 정보이다.
- P1은 원곡 찾기 프로세스를 적용 할 정보이다.
- P2는 비율분배를 적용할 정보이다.
- D는 미 매칭되었지만 UCI 표준음악정보와 권리음악정보 모두 매칭되지 않는 매칭 불가능 정보이다.
- 매칭 불가능 정보는 전체 미 분배 정보의 Noise 정보로 연제협의 분배정책에서 비율분배 할 수 있다.
- UCI는 미 매칭되었지만 UCI 표준음악정보와 매칭된 정보이며 임시 권리정보로 등록될 정보이다.
| 분류코드 | 설명 |
|---|---|
| F1 (정규앨범) | 곡, 가수, 앨범명의 매칭율이 높아 매칭이 확정 가능성이 높은 영역 |
| F2 (편집앨범) | 곡, 가수명의 매칭율이 높지만 앨범명의 매칭율이 낮은 편집앨범으로 권리자 레벨에 따라 매칭 확정 가능성이 높은 영역 |
| E1 (가수명 검증) | AI 학습모델에 의해 가수명 검증이 필요한 영역 |
| E2 (앨범명 검증) | AI 학습모델에 의해 앨범명 검증이 필요한 영역 |
| E3 (가수, 앨범명 검증) | AI 학습모델에 의해 가수와 앨범명 검증이 필요한 영역 |
| P1 (원곡 매칭) | AI 학습모델에 의해 원곡 찾기 프로세스가 필요한 영역 |
| P2 (곡명만 매칭) | 곡명만 매칭된 정보로 비율 분배 대상인 영역 |
| D (매칭 불가능) | 매칭 불가능 영역으로 Noise 정보의 속성을 가지며 연제협과 협의 후 비율분배 대상인 영역 |
- P1은 AI 검증을 통해 확정되면 F3가 된다.
- P2는 AI 검증을 통해 확정되면 F4가 된다.
AI 검수 학습모델 수립
AI 검수 프로세스는 String Searching 알고리즘과 AI 학습모델을 순환형으로 구성하여 검수의 정확율을 향상시키고 자동화한다.

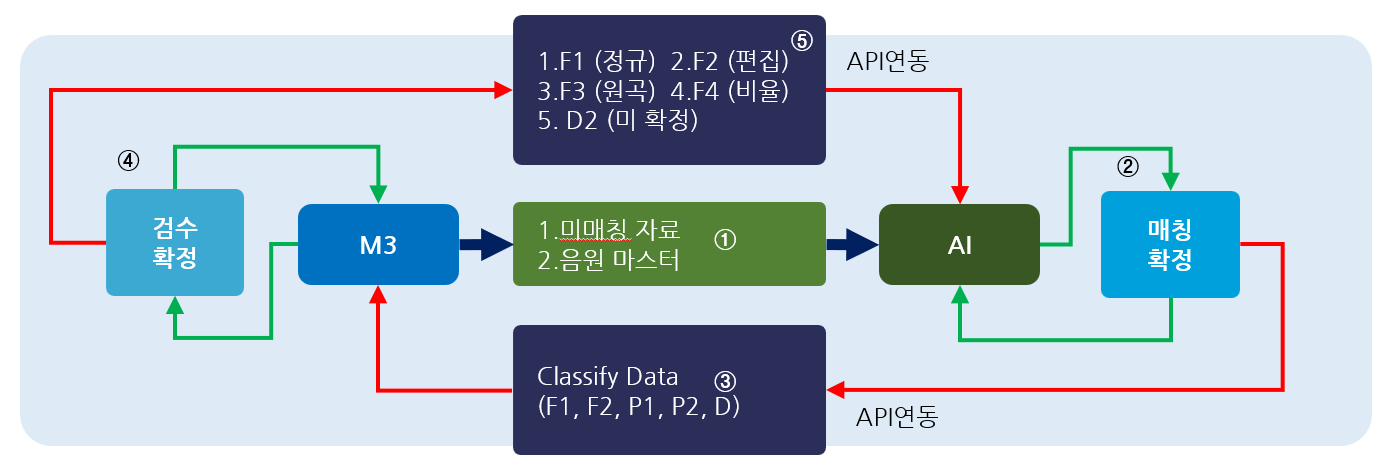
- ① 1.미 매칭 자료, 2.권리음악정보 제공
- ② 딥러닝 방식의 매칭 및 매칭 정보 1차 확정 내부 프로세스
- ③ 매칭 정보 Classify 음악 분류 및 UCI 표준음악정보 매칭
- ④ 매칭 정보 검수 및 학습을 위한 D2 정보 Feedback
- ⑤ 제공받은 ④ 데이터에 대하여 AI 검수를 통한 최종 확정
딥러닝을 적용한 매칭 프로세스
매칭 프로세스 : 곡명, 가수명, 앨범명에 대한 String Searching Matching Process이며 곡명의 매칭율이 100%를 기본 값으로 하고 가수명과 앨범명의 매칭율을 구한다.
Classify : 매칭율과 Entropy 값을 계상하여 음악 분류값을 정의하고 F1(정규), F2(편집), E1(가수명 검증), E2(앨범명 검증), E3(가수, 앨범명 검증), P1(원곡매칭), P2(곡명만 매칭, 비율분배대상), D1(재매칭, 비율분배), D2(UCI 표준음악 매칭)으로 1차 분류한다.
AI 검수 : 음악 분류 값을 AI 집중 검수이며 가수명과 앨범명을 딥러닝을 적용하여 AI로 검증하여 확정하고 확정된 값을 피드백하여 학습한다.
*학습데이터 : 학습데이터는 기존 확정된 값과 Classify로 분류된 값을 검수하여 확정한 값으로 안다.
Entropy 값에 대한 AI 검수 프로세스
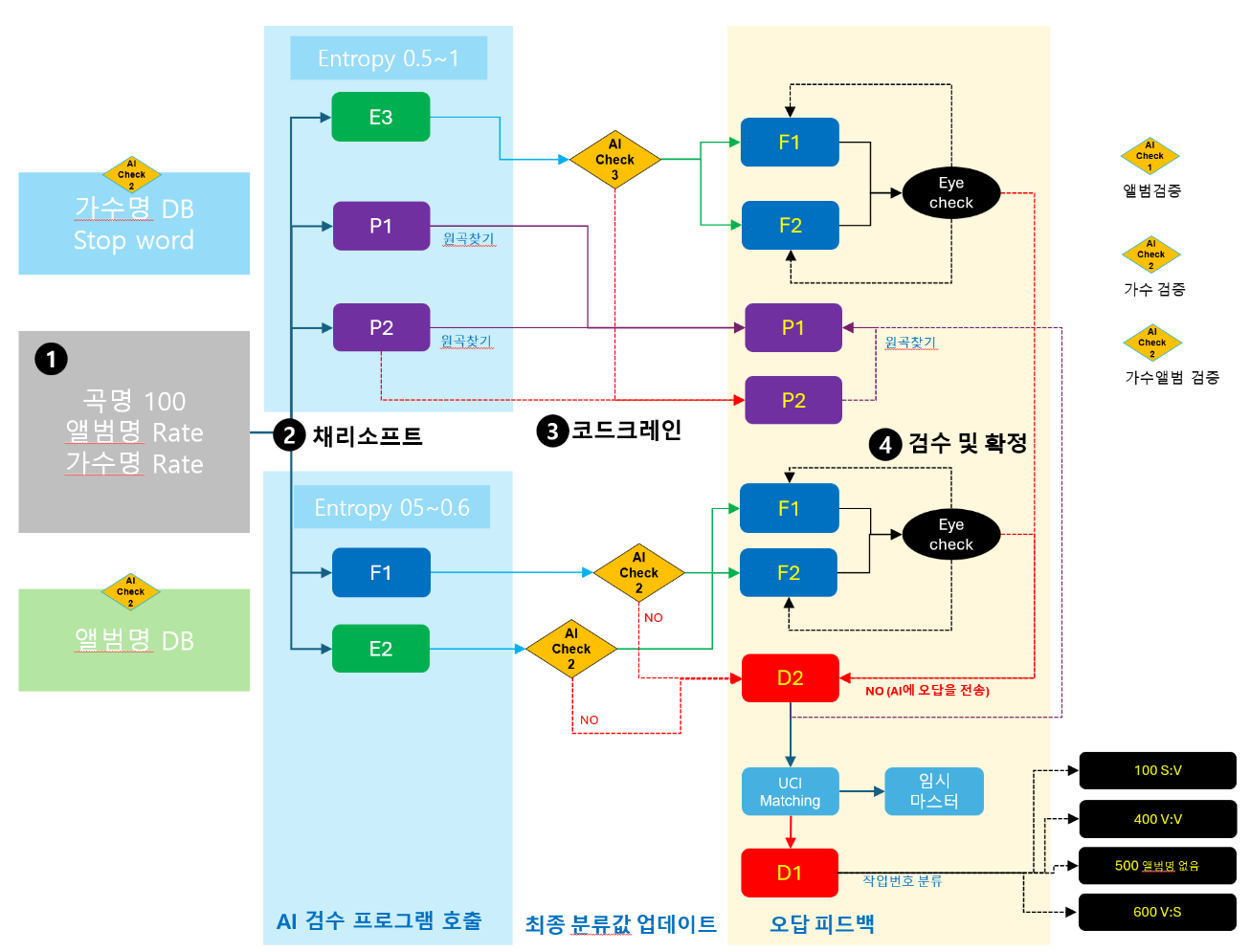
원곡찾기 프로세스
P1. P2에 해당하는 정보는 원곡찾기 프로세스를 적용한다.
원곡찾기 : 권리자레벨이 ML, LL, IL 이고 발매일이 가장 빠른 곡을 매칭한다.